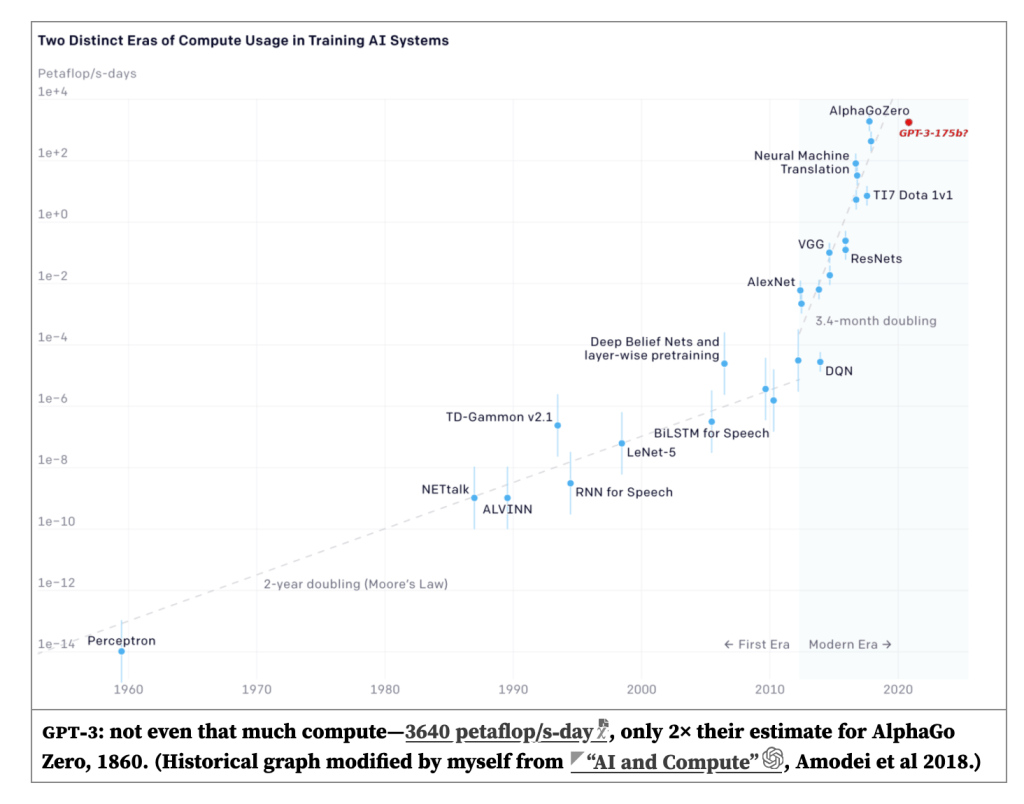
start from Gwern here https://www.gwern.net/newsletter/2020/05#gpt-3
parameters scaling in GPT-3 does not run into linear scaling of performance nor dimishing returns. Rather it shows metalearning enhancing the performance
It was forecast by Moraves and since we are in a fat tail phenomenon this holds true: “the scaling hypothesis is so unpopular an idea, and difficult to prove in advance rather than as a fait accompli“. Before GPT-3 another epiphany on the scaling was the google cat moment which started the deep learning craze
Another idea which I like is that models like GPT-3 are definitely cheap and if they show superlinear growth it is a no brainer to go for bigger and more complex models, it is along way before matching the billions of expenses for Cern or nuclear fusion.
Carig Venter synthetic bacteria project cost us 40 milion, ground braking orojects costing so little should not be foregone
BTW to grasp the idea of how there could be a scaling benefit in growing deep learning sizes, go no further that a simple, unfounded but suggestive analogy with Metcalfe law of networks, network value grows with the square of nodes.